System Management Utility Functions
This program can be used to perform a variety of different functions on existing files or create (define) new ones. However, it is limited to accessing files within the Dynamo installation directory, which is typically U/CDI.
Since this program can erase or initialize data files, access should be
restricted.
Entering File Name
In addition to entering a file name, on systems such as Linux that include the 'locate'
function, you can type "L" (capitalized followed by a space), and then the file
name to quickly display all occurrences of the file on the disc. You can then
select the desired file from the list to perform a variety of operations on that file. On UNIX systems, you can enter "F" (capitalized followed by a space) and the file
name to use the 'find' function that will search for various copies of the file. Searching for files by file type is also supported (e.g. "L .txt" will return a list of all TEXT files). Note that this option is based on the directory
database that is typically updated once each night. Therefore, this list will
exclude files created since the last database update.
You can enter a folder name, or a folder name plus starting characters of
a file name, followed by F2 to explore the files in the folder specified.
The operator can select the desired file by highlighting the desired file name
in an alphabetical list of files in the folder. Select the ".." file
to select the parent directory of your current directory . Select the "." file to select the
directory itself.
When a job folder is active, F5 will display files in the active job folder.
Defining new files
If the file name entered does not exist, you can use the File Utility to create, or
define, the file. If the file can be found in the data dictionary, then
it will be defined based on the data dictionary information, otherwise the
operator will be prompted to enter the file characteristics needed to define
the file.
If you have job/project folders, with the format J/[Project#], then you
will have the option to define the new file or program in the active job
folder. The J menu option is used to activate a particular job.
Options for Existing Files
The options available vary by file type and operating system.
Display File Information
Display Template Information
Display_Key_Structure
Display Keys
Display/Maintain/Print Data
Display Sessions using File
Maintain
Move
Copy
Rename
Initialize (Clear All Records)
Erase
File Integrity Test & Record Length Analysis
Clear Unused Records
Rebuild File from First Field in Data Area
Verify Data to Template
Compute Field Sizes
Email File as Attachment
| File Utility Options |
| Display File Information |
Displays information about the file. The contents of
the view will vary by file type and operating system.
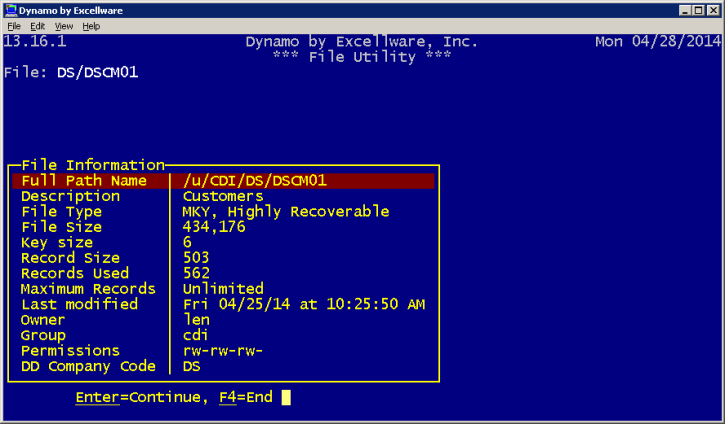
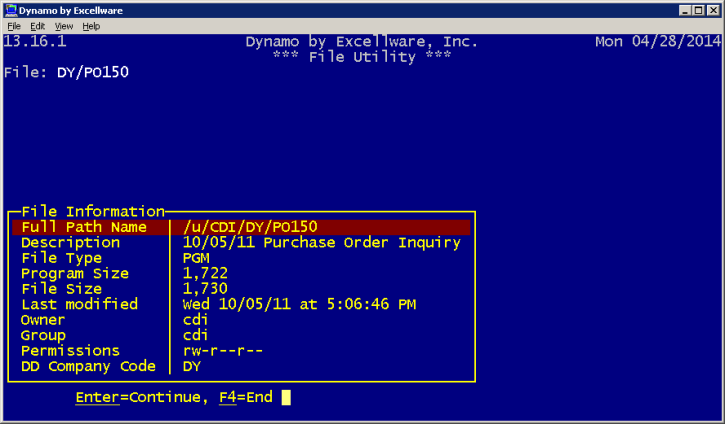
|
| Display Template Information |
The template will be displayed, with the source of the template
information displayed in the window border. Templates retrieved
from a template file will indicate the template file name.
Templates retrieved from the Data Dictionary will indicate the company
code and Data Dictionary file (DD11) where the template information was
obtained.
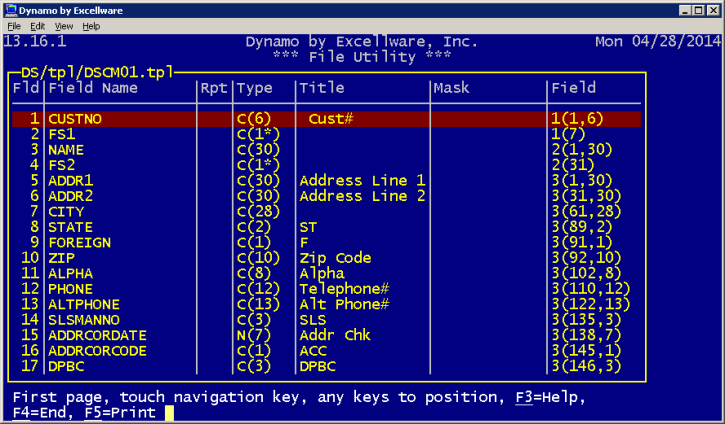
|
| Display Key Structure |
For multi-keyed file types, the key structure will be
displayed. For traditional files with field separators, the field,
offset, and length can be used. For template based files, whether
field separators are used or not, the field name will be displayed.
The KeySubst column indicates the position of the segment within the
key.
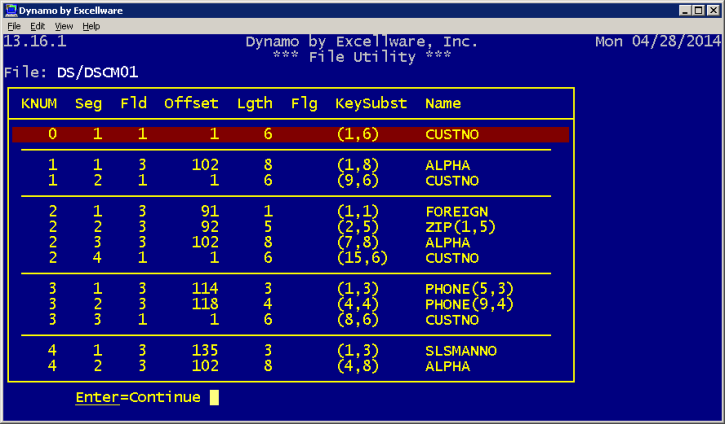
|
| Display Keys |
This option can be used to display the keys to a file.
The operator can choose which KNUM for files with multiple KNUMs.
The operator can indicate the starting key. Use the Display
Records option when the key contains binary data, and this option is not
very useful in that situation, although the key will be displayed in
hexadecimal format. In the example below, the ??? represent the
binary date, and the hexadecimal value of the key is displayed to the
right of the actual key.
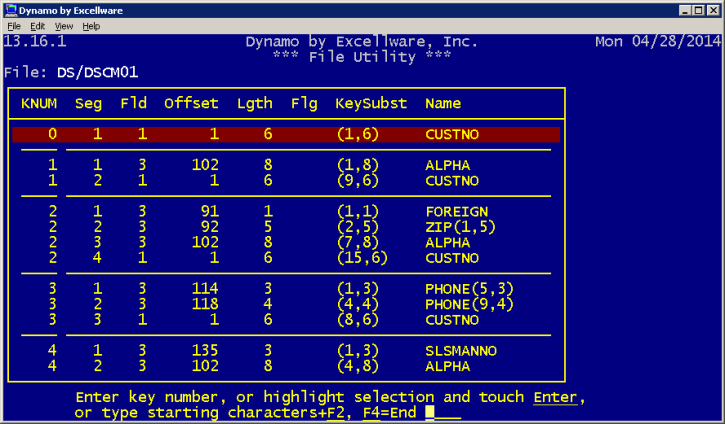
|
| Display/Maintain/Print Data |
This option can be used to display data for files with a
template. You can display the records, print them to a printer, or
save the selected records in a data file. You can select the
fields to be included, and the order that the fields will appear.
You can scroll to the right to view additional columns that do not fit
on the initial display. You can highlight a record to view a
record, change fields within a record, or delete a record. You can
'clone' a record in the multi-keyed file by changing a segment in the
primary key. You will be given the option to delete the original
record.
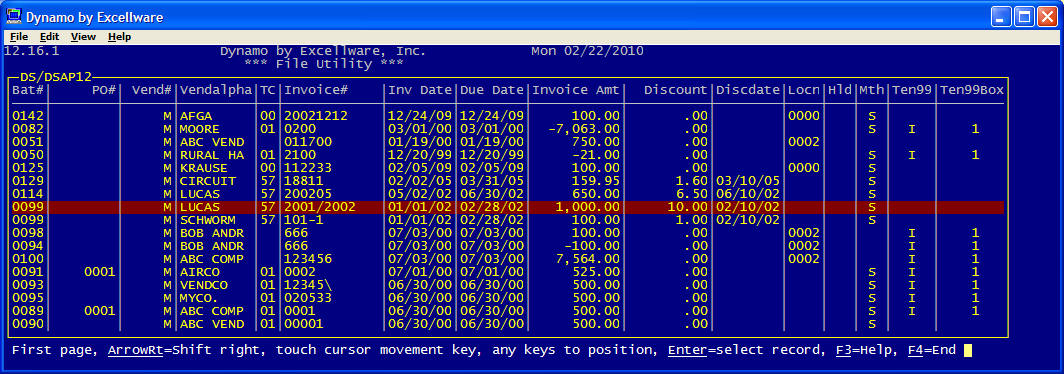
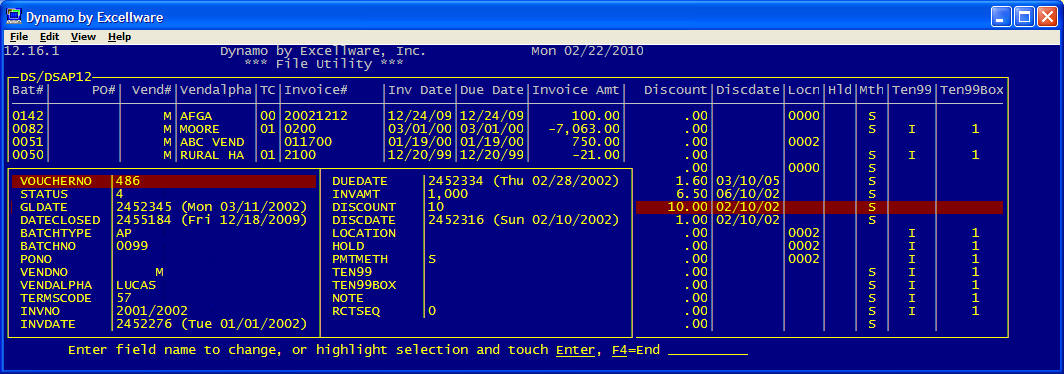
In addition to choosing an existing KNUM, this option also allows you to
create a WHERE clause to select the records desired. Note that you
can enter field names without the string variable, i.e., STATUS$
not REC.STATUS$. You can also use the F2 option to
paste the field names into the WHERE clause.
|
| Display Sessions using File |
On selected systems, this option can be used to display what
sessions have the file open.
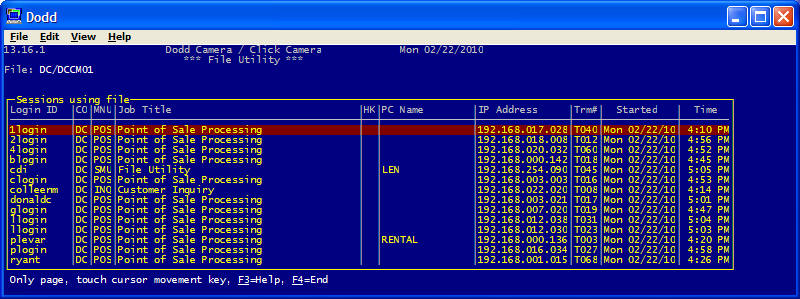
|
| Maintain |
This option enables adding records, deleting records, or modifying existing records in a file. |
| Move |
This option is used to move a file to another directory, and optionally, change the characteristics of the file, such as key size and structure, maximum number of records, and number of characters per record. The file name may be changed or left the same. This option performs a record-by-record copy and will erase the original file after the copy is completed. |
| Copy |
This function is similar to the Move option, except the original file is not erased.
Note that for certain file types, the new file type may be specified as STR in which case IOLIST based files will be converted to comma separated value (CSV) flat files to export to another system. |
| Initialize (Clear all records) |
This function removes all records in the file. The file remains on the disc. |
| Rename |
Rename allows the operator to change the name of a file. The new file name must be located on the same file system as the original file. In some cases it is necessary to provide the complete path for the new name. |
| Erase |
This function erases the entire file from the disc. |
| File Integrity Test & Record Length Analysis |
This option will verify that when reading through the file sequentially, each record is encountered only once, and that each key is larger than the previous key. This is normally true on direct access files, but in the case of a hardware malfunction, power failure, etc., the file may become damaged.
Since some keyed files traditionally have the first field of the data the same as the key, this option also checks to see if the first field matches the key. For IOLIST based files that have numeric or variable length string fields, the number of characters required per record may be less than the number defined. This option also computes the required number of characters per record. |
| Clear Unused Records |
For Direct (DIR) files, the data area of a file is not initialized when the file is defined. This option will clear the data area of a DIR file so that when processing files in indexed order, only active records with a key will be processed. |
| Rebuild File From First Field in Data Area |
If the key area of a DIR file becomes corrupted and the first field is the same as the key, this option will copy the file using only the data area to rebuild the file. This would only be required if the file was corrupted due to hardware, power, or other system failure. |
| Verify Data to Template |
This option is used for files that have a template in order to confirm that each record of the file meets the definition criteria of the template. |
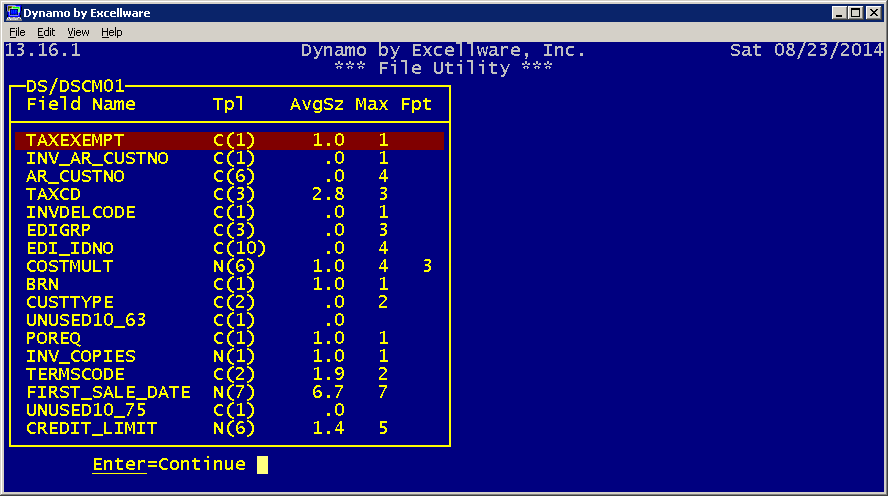
| Compute Field Sizes |
This option is used for data files with templates to compute the average and maximum number of characters used for each field in the file. It also computes the maximum number of fractional positions for numeric fields.
|
| Email file as attachment |
This option will attach the file to an email. |
